In a typical modern enterprise, there would be multiple systems producing data in different formats and multiple systems which has to consume these data. Integrating these systems using a full mesh topology will be complicated owing to the myraid of protocols (HTTP,gRPC, Rsocket, JDBC, REST, TCP etc) and data formats (JSON, AVRO, CSV, Binary). Apache Kafka is designed to solve the data integration problem which arises when the number of systems producing and their corresponding consumers need to be integrated.
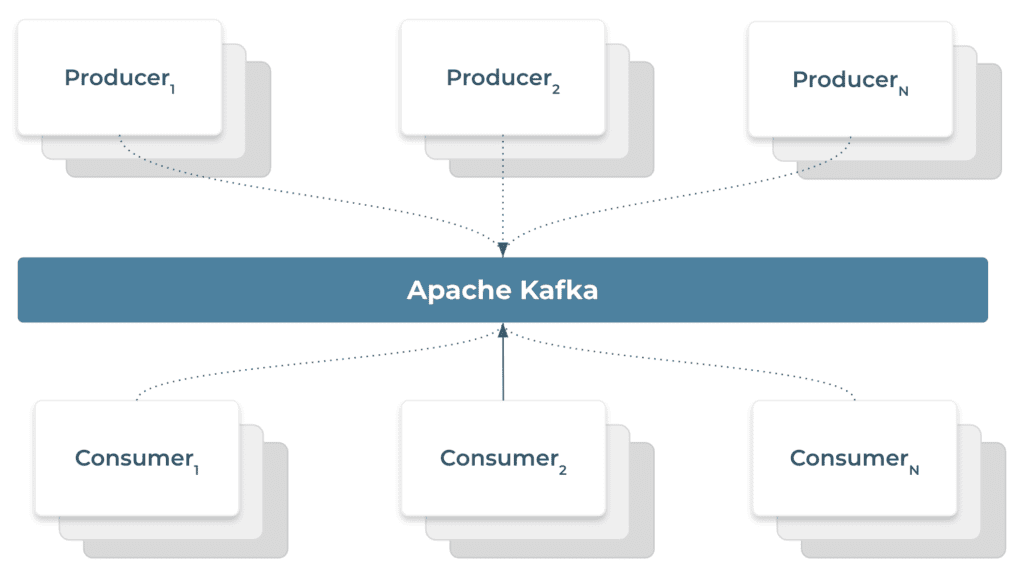
It can be used as a data integration layer such that the system producing the data can publish their data to an Apache Kafka Topic while consumer systems can subscribe to this topic to receive data.
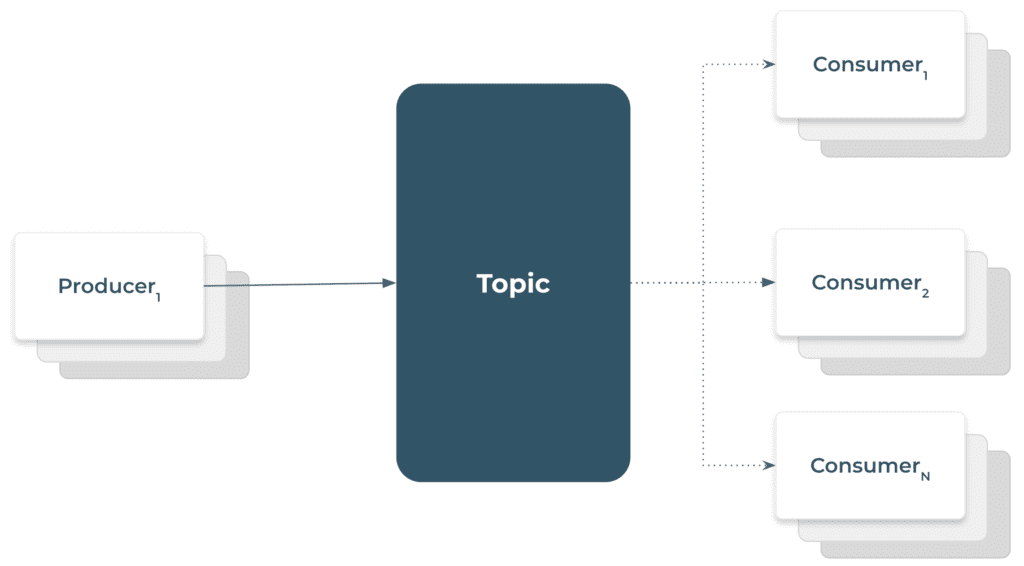
Within Kafka, a topic is used to organize related events. They can be equated to SQL Tables in a relational database. However, as compared to a table in a relational database, we cannot query a Kafka topic. All applications that send data to a topic are called producers. Whereas applications receiving data by subscribing to a topic are called consumers. A single topic can have multiple consumers as shown below.
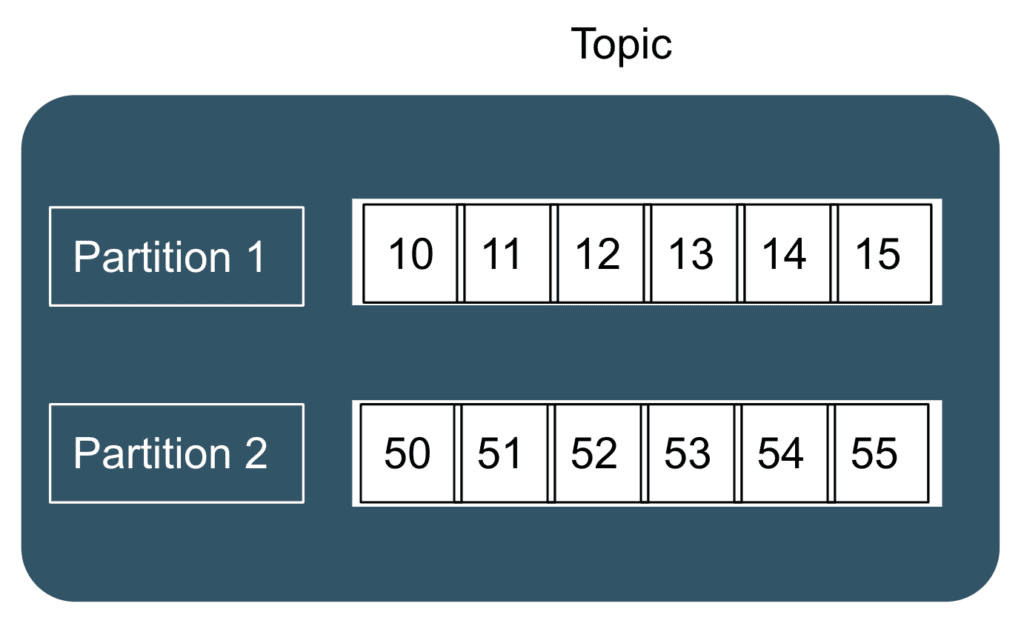
A Topic within Kafka is divided into partitions. The number of partitions within a topic is specified during the creation of a topic. It is important to note that Kafka guarantees the ordering of messages only within a partition, but not across partitions.
Further, the topics can be replicated across different Kafka Brokers for high availability. A high-level view of a producer producing to a set of topic partitions replicated across three brokers is shown in the figure below
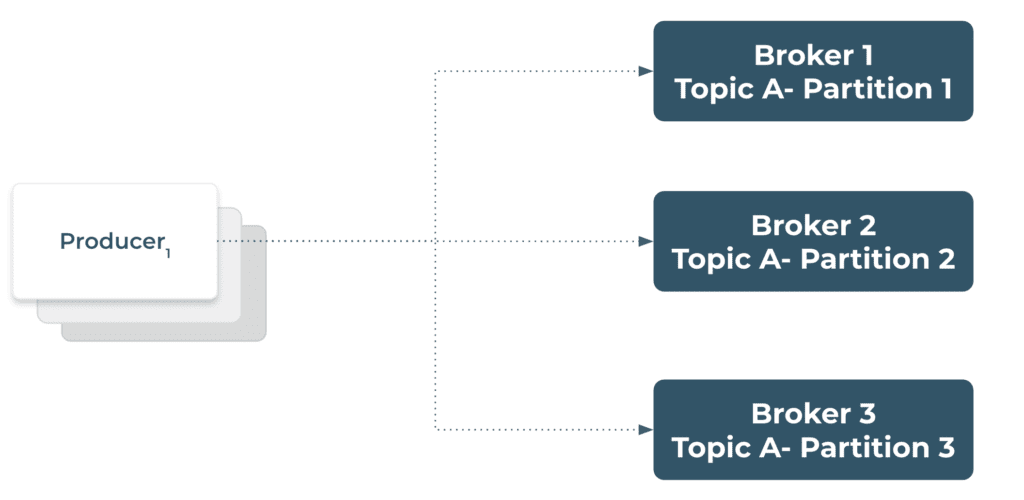
Producers, Topics and Partitions
A producer sends a message to a topic and the message is distributed to a particular topic depending on the value of the messageKey. Each message sent to Kafka has an optional key and a value. If the is not specified by the producer, then messages are distributed across the topic in a round-robin fashion. However, if a key is specified by the producer, then all messages having the same value of the key ends up in the same partition.
Consumer, Consumer Groups and Partitions
Consumers reads data from Kafka Topics. In effect, consumers read from one or more partitions and data is read in order within each partition from lower offset to higher offset. Although the message read order is still guaranteed within each individual partition, the message order across many partitions is not guaranteed if the consumer consumes data from more than one at once.
For the purpose of horizontal scalability, consumers can be grouped together in a consumer group. A Kafka consumer group is made up of consumers who are a part of the same application. For example, they can be different instances of the same (micro) service which is consumed from a topic. As discussed above, a topic typically has numerous partitions. For Kafka consumers, these partitions serve as a parallelism unit. The advantage of using a Kafka consumer group is that the group’s members will work together to divide the effort of reading from various partitions.
For grouping consumers with the same consumer group, they must have the same group.id property. A GroupCoordinator and a ConsumerCoordinator are automatically used by Kafka Consumers to allocate consumers to a partition and make sure load balancing is accomplished across all consumers in the same group. A consumer from a consumer group can be assigned many topic partitions, but it’s vital to note that each topic partition is only assigned to one consumer inside a consumer group.
Consider four partitions of a topic and three consumers in a consumer group as shown in the diagram below:
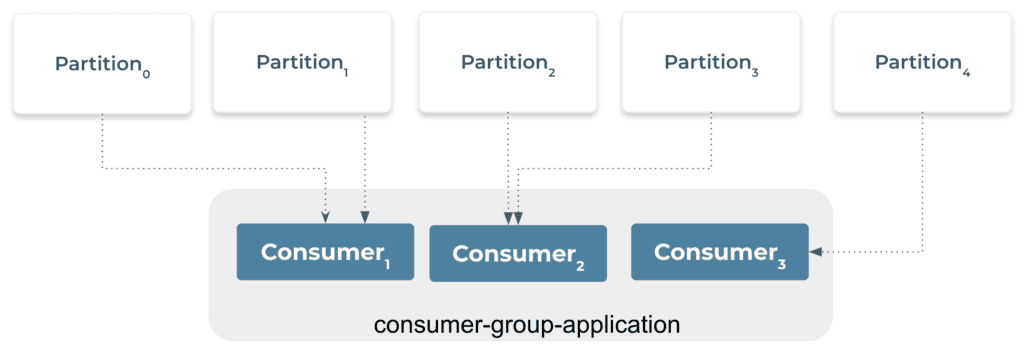
Partitions 0 and 1 have been assigned to Consumer 1 of the consumer group consumer-group-application-1, while Partitions 2 and 3 have been assigned to Consumer 2, and Partition 4 has been assigned to Consumer 3. Messages from Partitions 0 and 1 are only received by Consumer 1, those from Partitions 2 and 3 are only received by Consumer 2, while messages from Partition 4 are only received by Consumer 3.
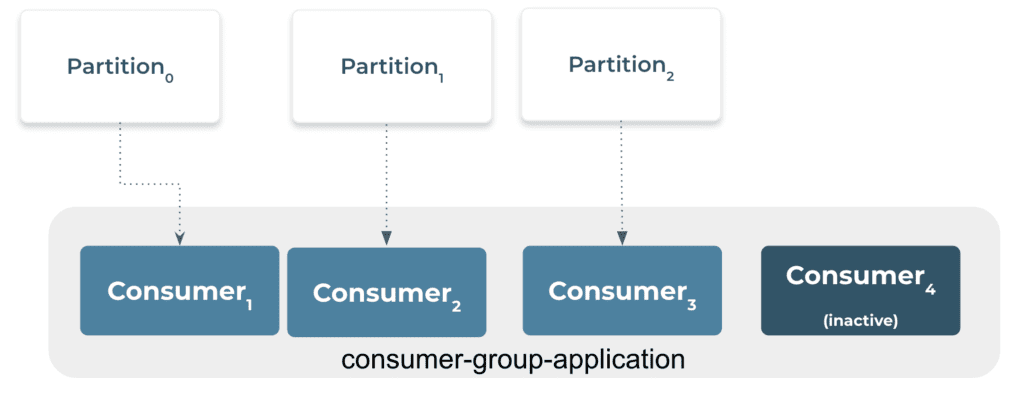
Some consumers will remain dormant as seen below if the number of customers exceeds the number of partitions of a topic. A consumer group typically contains the same number of consumers as partitions. When constructing the topic, we should add more partitions if we want more customers and higher throughput. If not, some of the consumers might continue to be inactive.